テキスト処理を業務で多用している私です。Bashでプログラムも書いたりしています。
awkを中心としたテキスト処理の手法を紹介します。
サンプルデータの準備
テストデータ生成
TM – WebToolsでサンプルデータを作成しました。

10項目からなる、10,000行のデータを用意しました。
ファイルレイアウトは以下の通りで、ファイル形式はUnix/Linux向けのカンマ区切りCSVとしました。
1 姓 2 名 3 フリガナ(姓) 4 フリガナ(名) 5 生年月日 6 年齢 7 郵便番号 8 都道府県 9 電話番号 10 Email
ファイル名変更
日本語がファイル名に含まれており扱いにくいので、以下のスクリプトでファイル名を変更します。
mv 'テストデータ - TM-WebTools.csv' testdata.csv
これで、”‘テストデータ – TM-WebTools.csv'”というファイルが”testdata.csv”というファイル名に変更できました。
区切り文字(カンマ)の除去
ファイル名を変更した”testdata.csv”の中を見てみると、フィールドがカンマ区切りになっています。カンマを以下のスクリプトで除去します。
ついでに先頭行に不要なレコードもあるため除去します。
awk 'NR>1' testdata.csv | sed 's/,/ /g' > list1.csv
これで、不要な1行目の削除と、カンマを半角スペースへと置換することができました。
awk ‘NR>1’ testdata.csv で testdata.csvというファイルの1行目以降を表示させています。
awkコマンドのNRはNumber of Recordsのことで、NR>1でレコードナンバーが1より大きい行を表示させています。その結果をパイプ( | )で渡し、sed ‘s/,/ /g’ で 「,」を「 」に置換しています。
そしてその結果を list1.csvというファイルに書き込むという処理をしています。
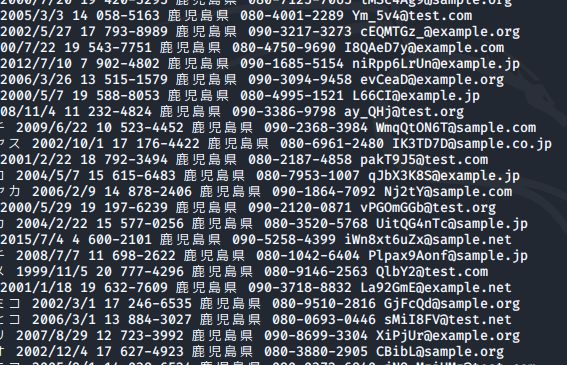
awk 'NR>1' testdata.csv の結果

awk 'NR>1' testdata.csv | sed 's/,/ /g' の結果

サンプルデータを処理
フィールド数を確認する
ファイルのフィールド数を確認します。成形されたファイルであればフィールド数はすべてのレコードで同じです。以下のスクリプトでフィールド数を確認できます。
awk '{print NF}' list1.csv | sort -u

awk ‘{print NF}’ で 各レコードのフィールド数が表示されます。
sort -u でフィールド数を並べ替えた後、重複した行を削除しています。
今回は成形されたテキストデータを使用していますので、この結果は10とでます。つまり、全レコードが10フィールド構成となっているデータということです。
レコード数を確認する
対象のテキストファイルの行数を調べます。
awk '{print NR}' list1.csv | tail -1
 awk ‘{print NR}’ で行数を表示します。その結果をパイプで渡し、tail -1 で最後の1行を表示することで、ファイルが何行なのかを確認することができます。今回は10,000行ありますね。
awk ‘{print NR}’ で行数を表示します。その結果をパイプで渡し、tail -1 で最後の1行を表示することで、ファイルが何行なのかを確認することができます。今回は10,000行ありますね。
行を指定してデータを表示する
表示したい行を指定するときに使います。
awk 'NR==9999' list1.csv

awk ‘NR==9999’ で9,999行目を指定しています。NR=9999ではなく、NR==9999とすることで、9999行目と一致するレコードという意味になります。
特定の文字を含む行数を確認
grep 宮城 list1.csv | awk '{print NR}' | tail -1
“宮城”という文字を含んだ行数を表示します。
list1.csvというテストデータには、名前や都道府県が含まれています。
“宮城”という文字は、名前にも都道府県にも存在するため、「宮城県を含んだ行数は?」という問いに対しての結果としては不正確になります。
特定のフィールドが特定の文字になっている行の表示
都道府県が宮城県となっている行を表示します。
awk '$8=="宮城県"' list1.csv

都道府県の項目は8フィールド目です。awk ‘$8==”宮城県”‘ で 8フィールド目が宮城県と一致する行を表示させています。
抽出したい行の都道府県フィールドが複数あった場合は以下のようにします。
例:都道府県が北海道と沖縄県の行を抽出
awk '$8=="北海道" || $8=="沖縄県"' list1.csv

特定のフィールドが特定の文字から始まる行の表示
awk '$1~/^宮城/' list1.csv

$1つまり1フィールド目(姓フィールド)が”宮城”という文字から始まる行を表示します。
「特定の文字から始まる」 を表現するには~/^〇〇/と書きます。
1フィールド目(姓フィールド)が”中”という文字から始まる行を表示した場合
特定フィールドが〇〇以下のレコードを表示する
年齢が20以下のレコードを表示させます。年齢の項目は6フィールド目です。
awk '$6<=20' list1.csv

フィールドを指定し、比較演算子を使用します。
さらに条件を加えてみます。
年齢が20以下、かつ、都道府県が鹿児島県となっているレコードを表示。
awk '$6<=20 && $8=="鹿児島県"' list1.csv

年齢が20以下の条件は先ほどと同じです。 論理演算子 && を使用してAND条件(かつ)を加えます。加える条件は、8フィールド目が”鹿児島県”となっていることです。
行数を表示する
元のテキストファイルの先頭フィールドに行数を加えます。
awk '{print NR,$0}' list1.csv

awk ‘{print }’ という書き方で、表示内容を指定できます。print の後に行数を意味するNRを書き、list1,csvの全フィールドを意味する$0を書きます。NRと$0の間はカンマ(,)で区切ることで、行数と姓フィールドの間に半角スペースができます。カンマで区切らなかった場合は、行数と姓フィールドが結合されます。
表示する行数を”No.XXXXXXX”という形式にした場合には、次のように書きます。
awk '{print "NO."NR,$0}' list1.csv

行数が50,001から始まるようにしたいよ。という場合は次のように書きます。
awk '{print NR+50000,$0}' list1.csv

テキスト処理でawkコマンドは非常によく使用します。awkを使用せずにテキスト処理を行うのは非常に困難ですし、習得すればするほどできることが増えて便利になる魔法のコマンドです。
私はまだまだ学習中ですが、皆さんの参考になれば幸いです。

コメント